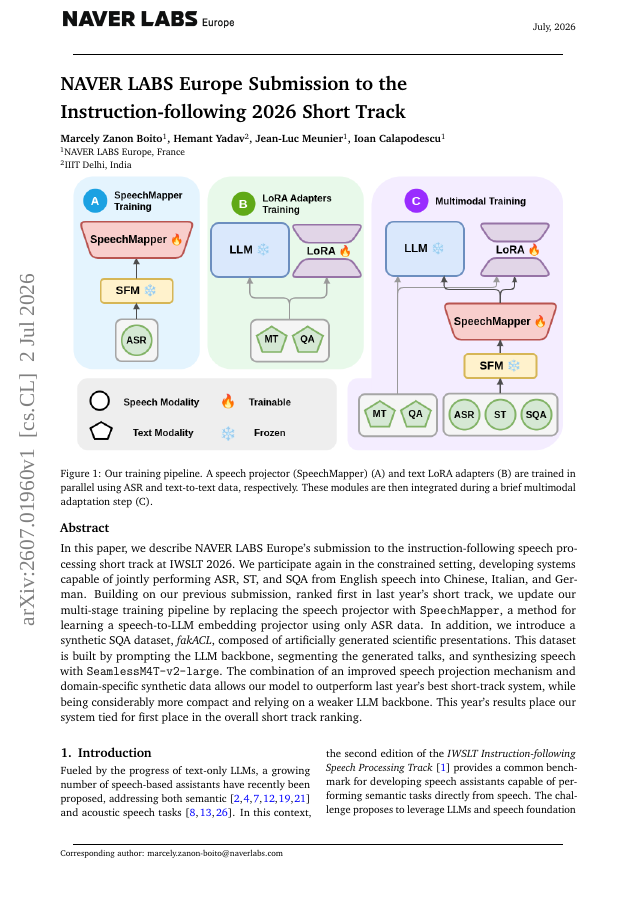
In this paper, we describe NAVER LABS Europe's submission to the instruction-following speech processing short track at IWSLT 2026. We participate again in the constrained setting, developing systems capable of jointly performing ASR, ST, and SQA from English speech into Chinese, Italian, and German. Building on our previous submission, ranked first in last year's short track, we update our multi-stage training pipeline by replacing the speech projector with SpeechMapper, a method for learning a speech-to-LLM embedding projector using only ASR data. In addition, we introduce a synthetic SQA dataset, fakACL, composed of artificially generated scientific presentations. This dataset is built by prompting the LLM backbone, segmenting the generated talks, and synthesizing speech with SeamlessM4T-large-v2. The combination of an improved speech projection mechanism and domain-specific synthetic data allows our model to outperform last year's best short-track system, while being considerably more compact and relying on a weaker LLM backbone. This year's results place our system tied for first place in the overall short track ranking.
NAVER LABS Europe Submission to the Instruction-following 2026 Short Track
In this paper, we describe NAVER LABS Europe's submission to the instruction-following speech processing short track at IWSLT 2026. We participate again in the constrained setting, developing systems capable of jointly performing ASR, ST, and SQA from English speech into…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.01960CC-BY-4.0
- TL;DR
- Semantic Scholar