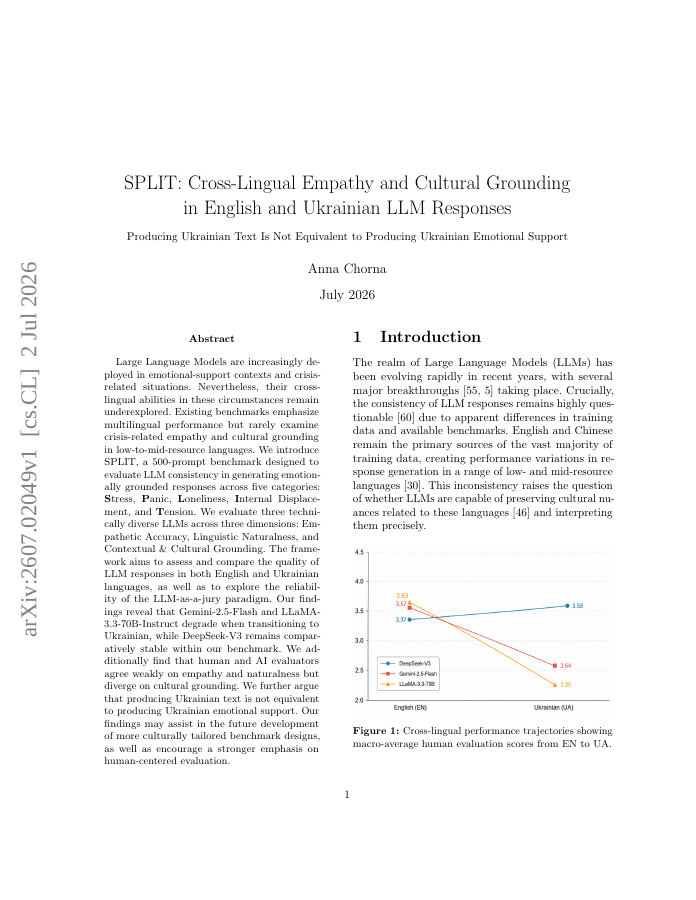
Large Language Models are increasingly deployed in emotional-support contexts and crisis-related situations. Nevertheless, their cross-lingual abilities in these circumstances remain underexplored. Existing benchmarks emphasize multilingual performance but rarely examine crisis-related empathy and cultural grounding in low-to-mid-resource languages. We introduce SPLIT, a 500-prompt benchmark designed to evaluate LLM consistency in generating emotionally grounded responses across five categories: Stress, Panic, Loneliness, Internal Displacement, and Tension. We evaluate three technically diverse LLMs across three dimensions: Empathetic Accuracy, Linguistic Naturalness, and Contextual & Cultural Grounding. The framework aims to assess and compare the quality of LLM responses in both English and Ukrainian languages, as well as to explore the reliability of the LLM-as-a-jury paradigm. Our findings reveal that Gemini-2.5-Flash and LLaMA-3.3-70B-Instruct degrade when transitioning to Ukrainian, while DeepSeek-V3 remains comparatively stable within our benchmark. We additionally find that human and AI evaluators agree weakly on empathy and naturalness but diverge on cultural grounding. We further argue that producing Ukrainian text is not equivalent to producing Ukrainian emotional support. Our findings may assist in the future development of more culturally tailored benchmark designs, as well as encourage a stronger emphasis on human-centered evaluation.
SPLIT: Cross-Lingual Empathy and Cultural Grounding in English and Ukrainian LLM Responses
Large Language Models are increasingly deployed in emotional-support contexts and crisis-related situations. Nevertheless, their cross-lingual abilities in these circumstances remain underexplored.
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.02049CC-BY-4.0
- TL;DR
- Semantic Scholar