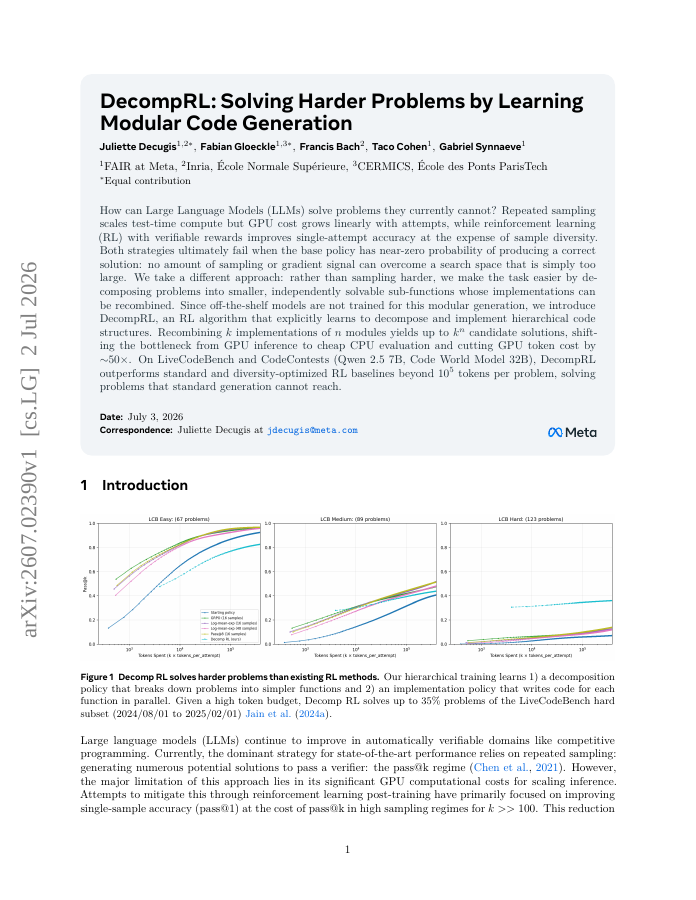
How can Large Language Models (LLMs) solve problems they currently cannot? Repeated sampling scales test-time compute but GPU cost grows linearly with attempts, while reinforcement learning (RL) with verifiable rewards improves single-attempt accuracy at the expense of sample diversity. Both strategies ultimately fail when the base policy has near-zero probability of producing a correct solution: no amount of sampling or gradient signal can overcome a search space that is simply too large. We take a different approach: rather than sampling harder, we make the task easier by decomposing problems into smaller, independently solvable sub-functions whose implementations can be recombined. Since off-the-shelf models are not trained for this modular generation, we introduce DecompRL, an RL algorithm that explicitly learns to decompose and implement hierarchical code structures. Recombining k implementations of n modules yields up to k^{n} candidate solutions, shifting the bottleneck from GPU inference to cheap CPU evaluation and cutting GPU token cost by \sim50\times. On LiveCodeBench and CodeContests (Qwen 2.5 7B, Code World Model 32B), DecompRL outperforms standard and diversity-optimized RL baselines beyond 10^5 tokens per problem, solving problems that standard generation cannot reach.
DecompRL: Solving Harder Problems by Learning Modular Code Generation
How can Large Language Models (LLMs) solve problems they currently cannot? Repeated sampling scales test-time compute but GPU cost grows linearly with attempts, while reinforcement learning (RL) with verifiable rewards improves single-attempt accuracy at the expense of sample…
- Preview
- Year
- 2026
- Hosting
- Full text hostedCC-BY-4.0
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2607.02390CC-BY-4.0
- TL;DR
- Semantic Scholar