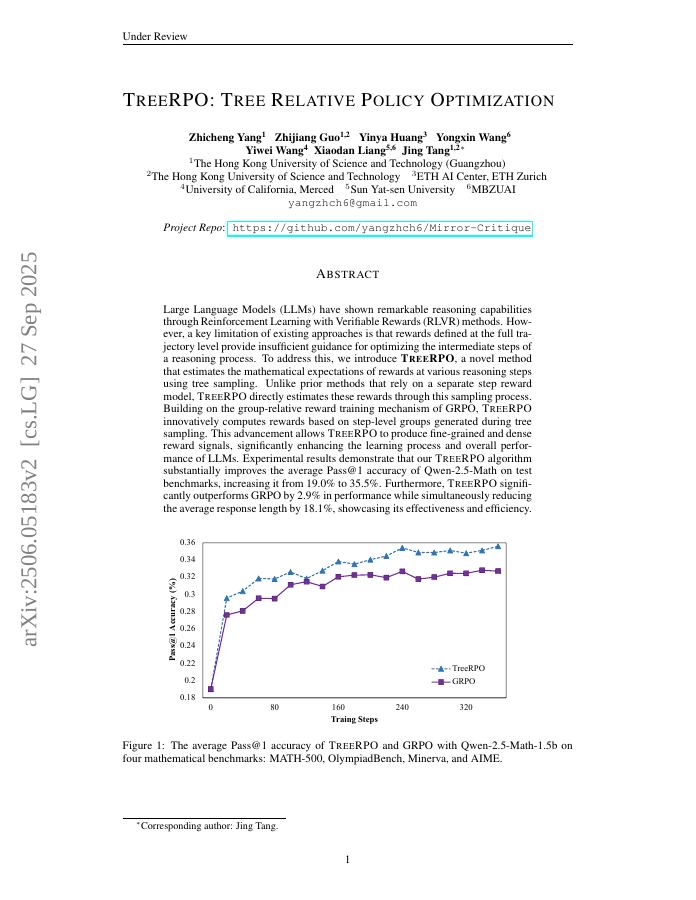
Large Language Models (LLMs) have shown remarkable reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR) methods. However, a key limitation of existing approaches is that rewards defined at the full trajectory level provide insufficient guidance for optimizing the intermediate steps of a reasoning process. To address this, we introduce \name, a novel method that estimates the mathematical expectations of rewards at various reasoning steps using tree sampling. Unlike prior methods that rely on a separate step reward model, \name directly estimates these rewards through this sampling process. Building on the group-relative reward training mechanism of GRPO, \name innovatively computes rewards based on step-level groups generated during tree sampling. This advancement allows \name to produce fine-grained and dense reward signals, significantly enhancing the learning process and overall performance of LLMs. Experimental results demonstrate that our \name algorithm substantially improves the average Pass@1 accuracy of Qwen-2.5-Math on test benchmarks, increasing it from 19.0% to 35.5%. Furthermore, \name significantly outperforms GRPO by 2.9% in performance while simultaneously reducing the average response length by 18.1%, showcasing its effectiveness and efficiency. Our code will be available at https://github.com/yangzhch6/TreeRPO.
TreeRPO: Tree Relative Policy Optimization
A novel method, TreeRPO, enhances LLM reasoning by estimating step-level rewards through tree sampling, improving accuracy and efficiency compared to existing approaches.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 6
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2506.05183ARXIV-DEFAULT
- TL;DR
- Semantic Scholar