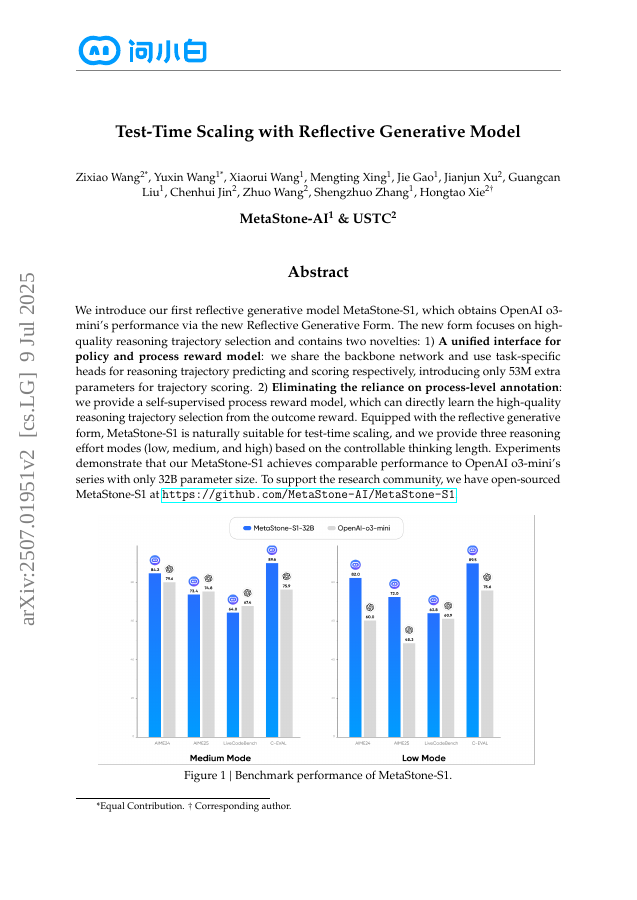
We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3-mini's performance via the new Reflective Generative Form. The new form focuses on high-quality reasoning trajectory selection and contains two novelties: 1) A unified interface for policy and process reward model: we share the backbone network and use task-specific heads for reasoning trajectory predicting and scoring respectively, introducing only 53M extra parameters for trajectory scoring. 2) Eliminating the reliance on process-level annotation: we provide a self-supervised process reward model, which can directly learn the high-quality reasoning trajectory selection from the outcome reward. Equipped with the reflective generative form, MetaStone-S1 is naturally suitable for test-time scaling, and we provide three reasoning effort modes (low, medium, and high) based on the controllable thinking length. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
Test-Time Scaling with Reflective Generative Model
MetaStone-S1, a reflective generative model using a self-supervised process reward model, achieves high performance with reduced parameters and supports test time scaling.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 11
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2507.01951v2ARXIV-DEFAULT
- TL;DR
- Semantic Scholar