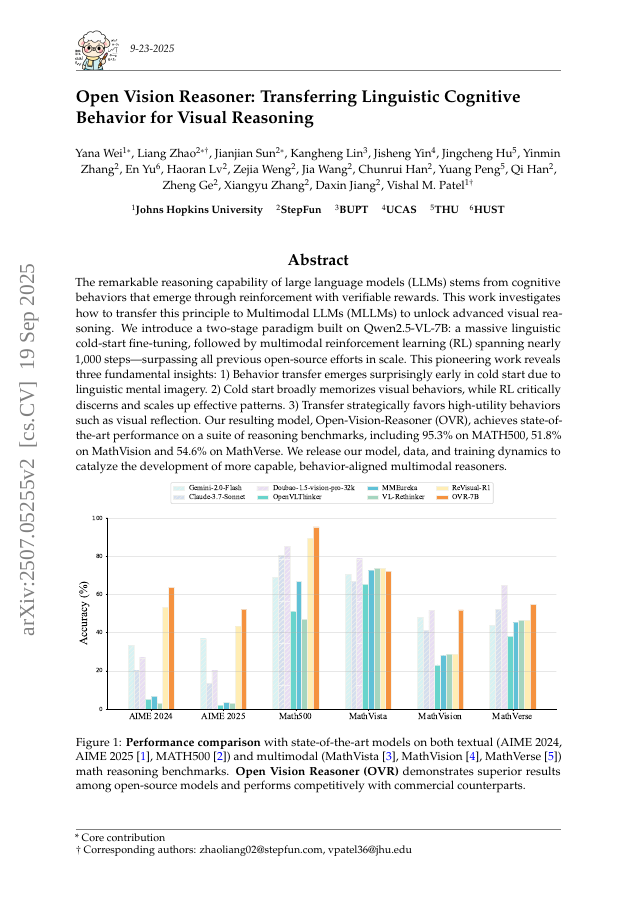
The remarkable reasoning capability of large language models (LLMs) stems from cognitive behaviors that emerge through reinforcement with verifiable rewards. This work investigates how to transfer this principle to Multimodal LLMs (MLLMs) to unlock advanced visual reasoning. We introduce a two-stage paradigm built on Qwen2.5-VL-7B: a massive linguistic cold-start fine-tuning, followed by multimodal reinforcement learning (RL) spanning nearly 1,000 steps, surpassing all previous open-source efforts in scale. This pioneering work reveals three fundamental insights: 1) Behavior transfer emerges surprisingly early in cold start due to linguistic mental imagery. 2) Cold start broadly memorizes visual behaviors, while RL critically discerns and scales up effective patterns. 3) Transfer strategically favors high-utility behaviors such as visual reflection. Our resulting model, Open-Vision-Reasoner (OVR), achieves state-of-the-art performance on a suite of reasoning benchmarks, including 95.3% on MATH500, 51.8% on MathVision and 54.6% on MathVerse. We release our model, data, and training dynamics to catalyze the development of more capable, behavior-aligned multimodal reasoners.
Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning
The remarkable reasoning capability of large language models (LLMs) stems from cognitive behaviors that emerge through reinforcement with verifiable rewards.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 18
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2507.05255ARXIV-DEFAULT
- TL;DR
- Semantic Scholar