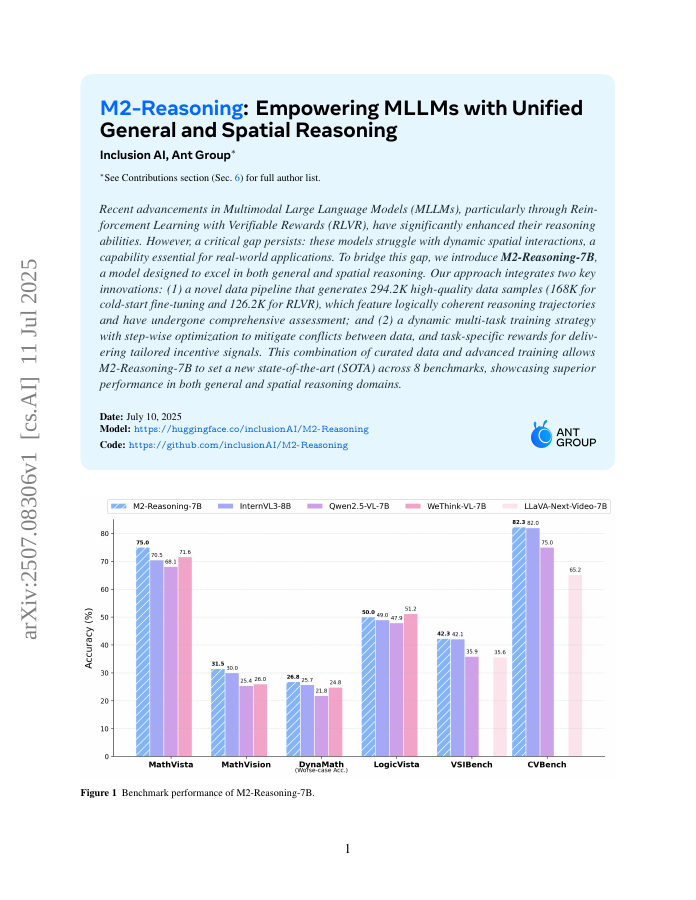
Recent advancements in Multimodal Large Language Models (MLLMs), particularly through Reinforcement Learning with Verifiable Rewards (RLVR), have significantly enhanced their reasoning abilities. However, a critical gap persists: these models struggle with dynamic spatial interactions, a capability essential for real-world applications. To bridge this gap, we introduce M2-Reasoning-7B, a model designed to excel in both general and spatial reasoning. Our approach integrates two key innovations: (1) a novel data pipeline that generates 294.2K high-quality data samples (168K for cold-start fine-tuning and 126.2K for RLVR), which feature logically coherent reasoning trajectories and have undergone comprehensive assessment; and (2) a dynamic multi-task training strategy with step-wise optimization to mitigate conflicts between data, and task-specific rewards for delivering tailored incentive signals. This combination of curated data and advanced training allows M2-Reasoning-7B to set a new state-of-the-art (SOTA) across 8 benchmarks, showcasing superior performance in both general and spatial reasoning domains.
M2-Reasoning: Empowering MLLMs with Unified General and Spatial Reasoning
M2-Reasoning-7B, a multimodal large language model, enhances spatial reasoning through a novel data pipeline and dynamic multi-task training strategy, achieving state-of-the-art performance across benchmarks.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 14
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2507.08306ARXIV-DEFAULT
- TL;DR
- Semantic Scholar