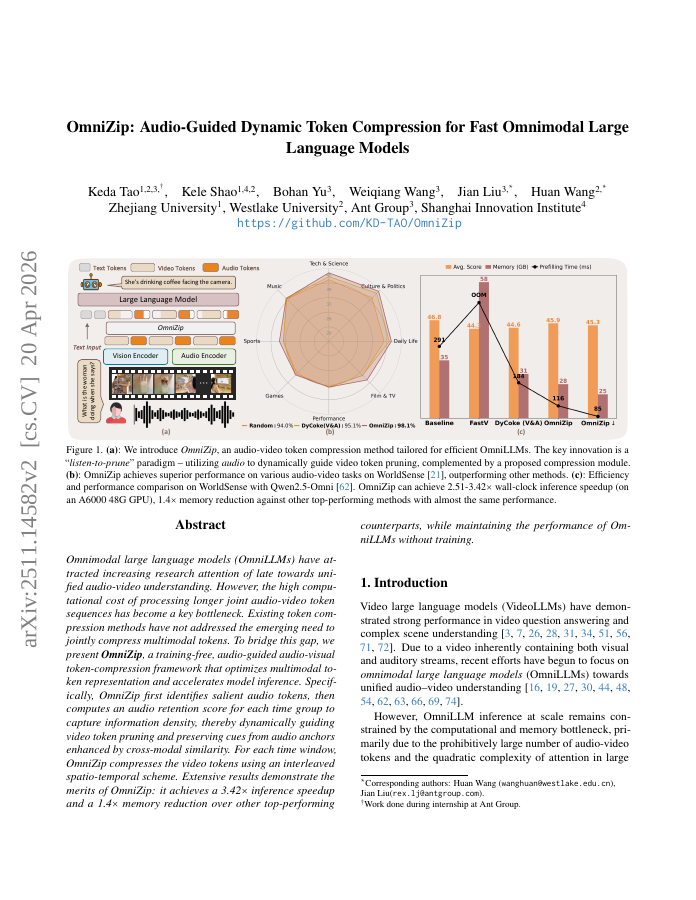
Omnimodal large language models (OmniLLMs) have attracted increasing research attention of late towards unified audio-video understanding, wherein processing audio-video token sequences creates a significant computational bottleneck, however. Existing token compression methods have yet to accommodate this emerging need of jointly compressing multimodal tokens. To bridge this gap, we present OmniZip, a training-free, audio-guided audio-visual token-compression framework that optimizes multimodal token representation and accelerates inference. Specifically, OmniZip first identifies salient audio tokens, then computes an audio retention score for each time group to capture information density, thereby dynamically guiding video token pruning and preserving cues from audio anchors enhanced by cross-modal similarity. For each time window, OmniZip compresses the video tokens using an interleaved spatio-temporal scheme. Extensive empirical results demonstrate the merits of OmniZip - it achieves 3.42X inference speedup and 1.4X memory reduction over other top-performing counterparts, while maintaining performance with no training.
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
OmniZip is a training-free framework that compresses audio-visual tokens by dynamically pruning video tokens based on audio retention scores, achieving significant inference speedup and memory reduction without sacrificing performance.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 6
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2511.14582ARXIV-DEFAULT
- TL;DR
- Semantic Scholar