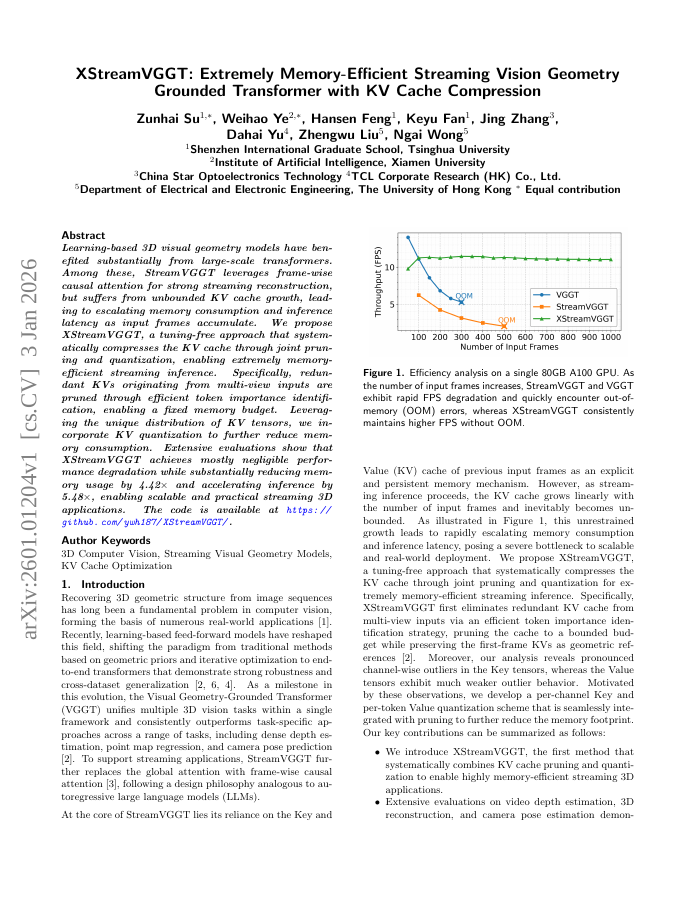
Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42times and accelerating inference by 5.48times, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
XStreamVGGT enables efficient streaming 3D reconstruction through systematic KV cache compression via pruning and quantization while maintaining near-optimal performance.
- Preview
- Year
- 2026
- Venue
- arXiv 2026
- Authors
- 8
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2601.01204ARXIV-DEFAULT
- TL;DR
- Semantic Scholar