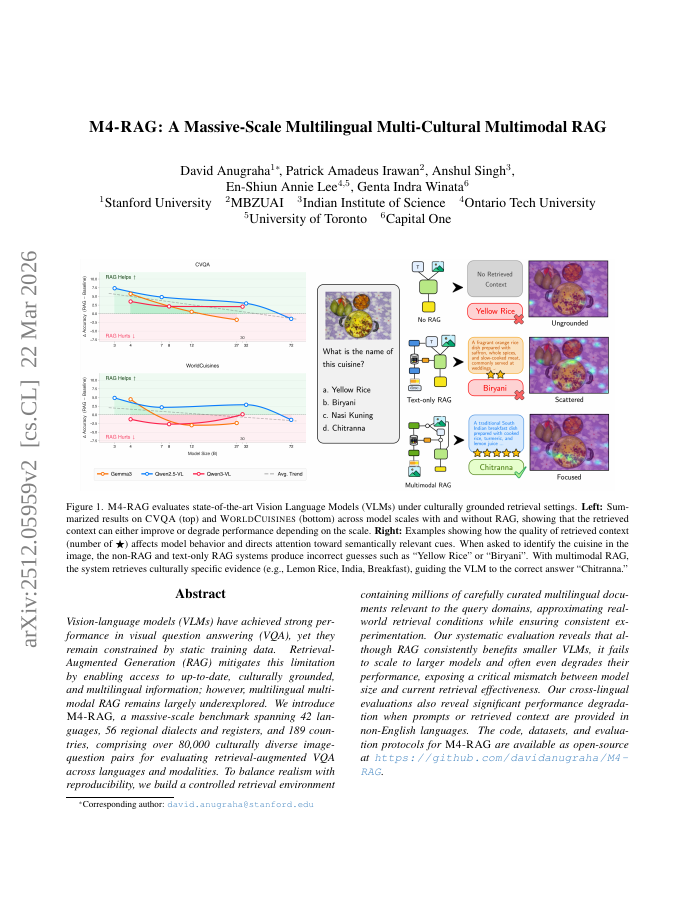
Vision-language models (VLMs) have achieved strong performance in visual question answering (VQA), yet they remain constrained by static training data. Retrieval-Augmented Generation (RAG) mitigates this limitation by enabling access to up-to-date, culturally grounded, and multilingual information; however, multilingual multimodal RAG remains largely underexplored. We introduce M4-RAG, a massive-scale benchmark spanning 42 languages, 56 regional dialects and registers, and 189 countries, comprising over 80,000 culturally diverse image-question pairs for evaluating retrieval-augmented VQA across languages and modalities. To balance realism with reproducibility, we build a controlled retrieval environment containing millions of carefully curated multilingual documents relevant to the query domains, approximating real-world retrieval conditions while ensuring consistent experimentation. Our systematic evaluation reveals that although RAG consistently benefits smaller VLMs, it fails to scale to larger models and often even degrades their performance, exposing a critical mismatch between model size and current retrieval effectiveness. Our cross-lingual evaluations also reveal significant performance degradation when prompts or retrieved context are provided in non-English languages. The code, datasets, and evaluation protocols for M4-RAG are available as open-source at https://github.com/davidanugraha/M4-RAG.
M4-RAG: A Massive-Scale Multilingual Multi-Cultural Multimodal RAG
Retrieval-Augmented Generation enhances visual question answering models by providing up-to-date information but faces challenges with multilingual scalability and performance degradation in non-English contexts.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 5
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2512.05959ARXIV-DEFAULT
- TL;DR
- Semantic Scholar