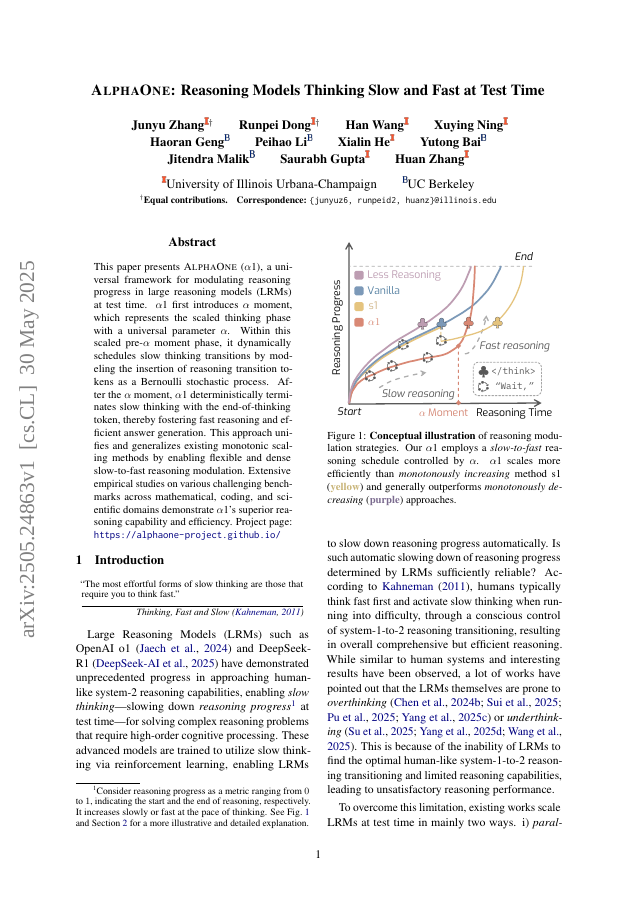
This paper presents AlphaOne (\alpha1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. \alpha1 first introduces \alpha moment, which represents the scaled thinking phase with a universal parameter \alpha. Within this scaled pre-\alpha moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the \alpha moment, \alpha1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate \alpha1's superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time.
- Preview
- Year
- 2025
- Venue
- arXiv 2025
- Authors
- 11
- Hosting
- Abstract onlyARXIV-DEFAULT
Cite
Notes
Only stored in your browser.
Attribution
- Abstract & full text
- arxiv.org/abs/2505.24863ARXIV-DEFAULT
- TL;DR
- Semantic Scholar